-
咨询电话
13592147543 -
微信扫一扫


新闻动态
线上四台机器同一时间全部 OOM,到底发生了什么?
常见问题 发布者:cya 2019-12-25 08:40 访问量:224
 微信
微信 微博
微博 人人网
人人网 腾讯微博
腾讯微博 QQ空间
QQ空间作者:码海
链接:https://mp.weixin.qq.com/s/B1EplSO2hTEoDAcPNtsGwA
圣诞快乐

案发现场
问题排查

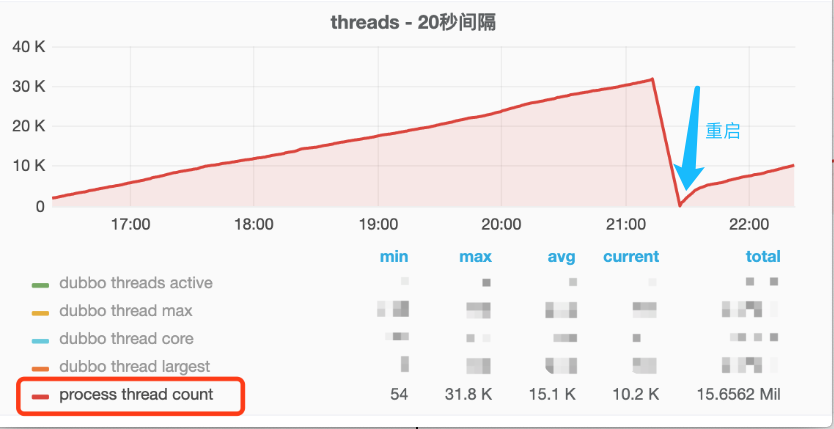

还原事发经过
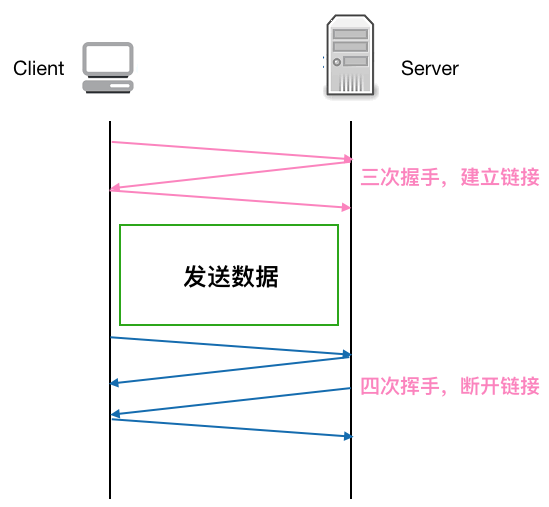
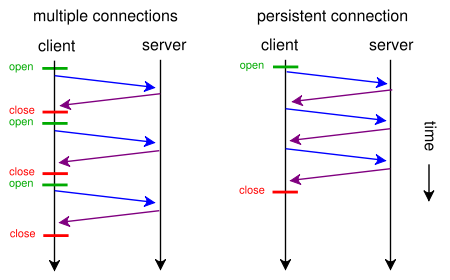
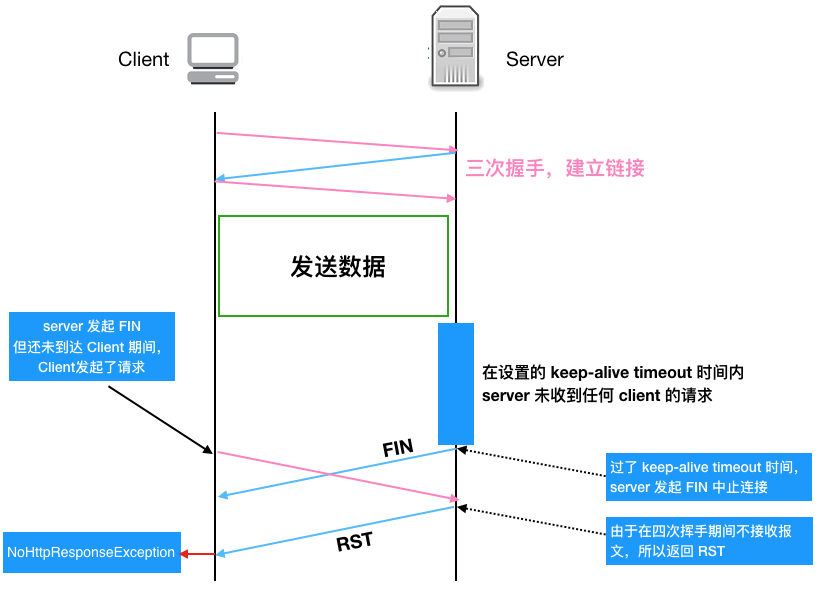
Makes this instance of HttpClient proactively evict idle connections from the
connection pool using a background thread.
问题解决
总结
文章连接: https://chenzhankj.com/cjwt/656.html
版权声明:文章由 晨展科技 整理收集,来源于互联网或者用户投稿,如有侵权,请联系我们,我们会立即删除。如转载请保留
